Soos Talks
Every two weeks, a VIS Lab member presents their research, recent results, or a topic they're exploring over sandwiches in an informal setting.
Why “Soos”? In Dutch, a soos is a social club or meeting place, an informal shortening of sociëteit (social society). Think of a youth club (jeugdsoos) or community hall where people gather for conversation, events, and shared activities. That spirit carries over here. Soos is the lab’s regular gathering point: a place to share work, hear what others are building, and stay connected. I organize the series, including speakers, sandwiches, and logistics, and have hosted over 20 talks during the past year across computer vision, multimodal learning, generative models, and more.
Below is a rolling archive of talks from the series — each card shows the title slide from that session.

Christoforos Spartalis
Jun 02, 2026

Danilo de Goede
Jun 02, 2026

Swasti Mishra
May 19, 2026

Gowreesh Mago
May 19, 2026

Christian Gumbsch
Apr 21, 2026
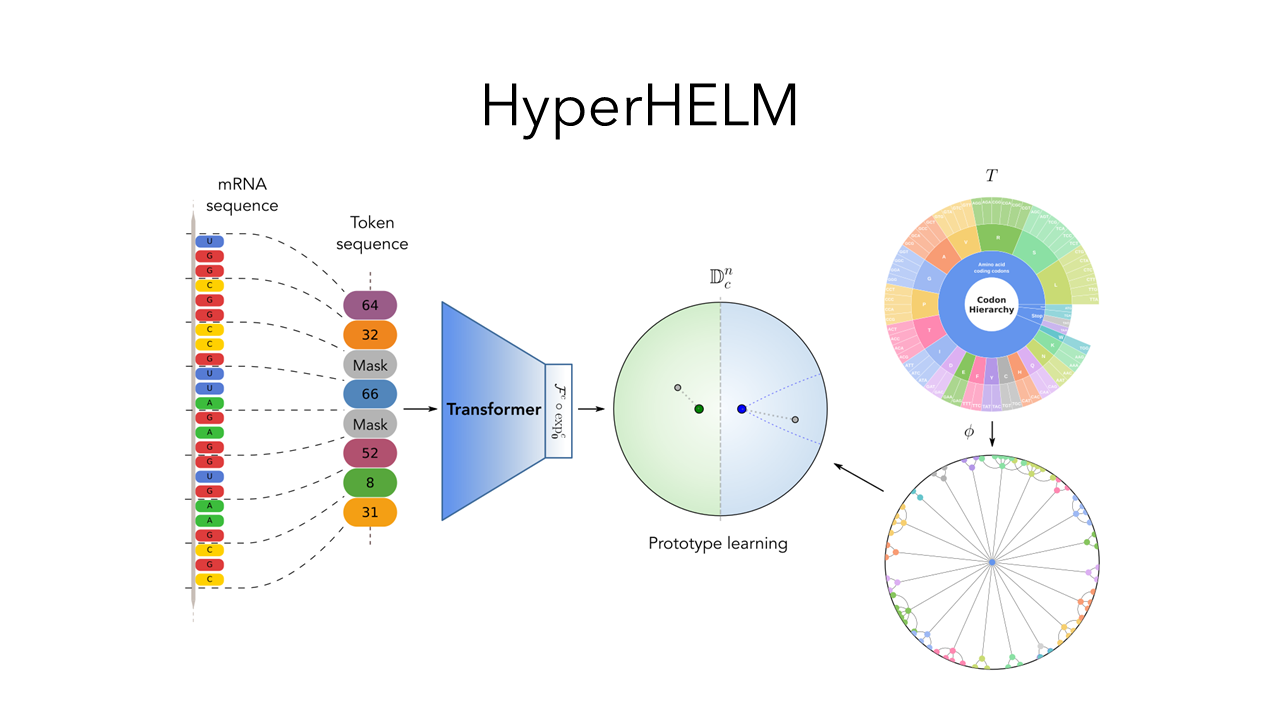
Max van Spengler
Apr 21, 2026

Alex Cherniavskii
Apr 07, 2026

Dimitris Karageorgiou
Apr 07, 2026

Mohammadreza Salehi
Mar 10, 2026

Leonard Barcellona
Mar 10, 2026

Walter Simoncini
Feb 24, 2026

Stefanos Achlatis
Feb 10, 2026

Riccardo Valperga
Jan 27, 2026

Samuele Papa
Dec 09, 2025

Christina Sartzetaki
Dec 09, 2025

Wenfang Sun
Nov 18, 2025

Emile van Krieken
Oct 07, 2025

Dheeraj Varghese
Oct 07, 2025